Lint, Test, Deploy: Building a dbt CI Pipeline with SQLFluff Style Checks

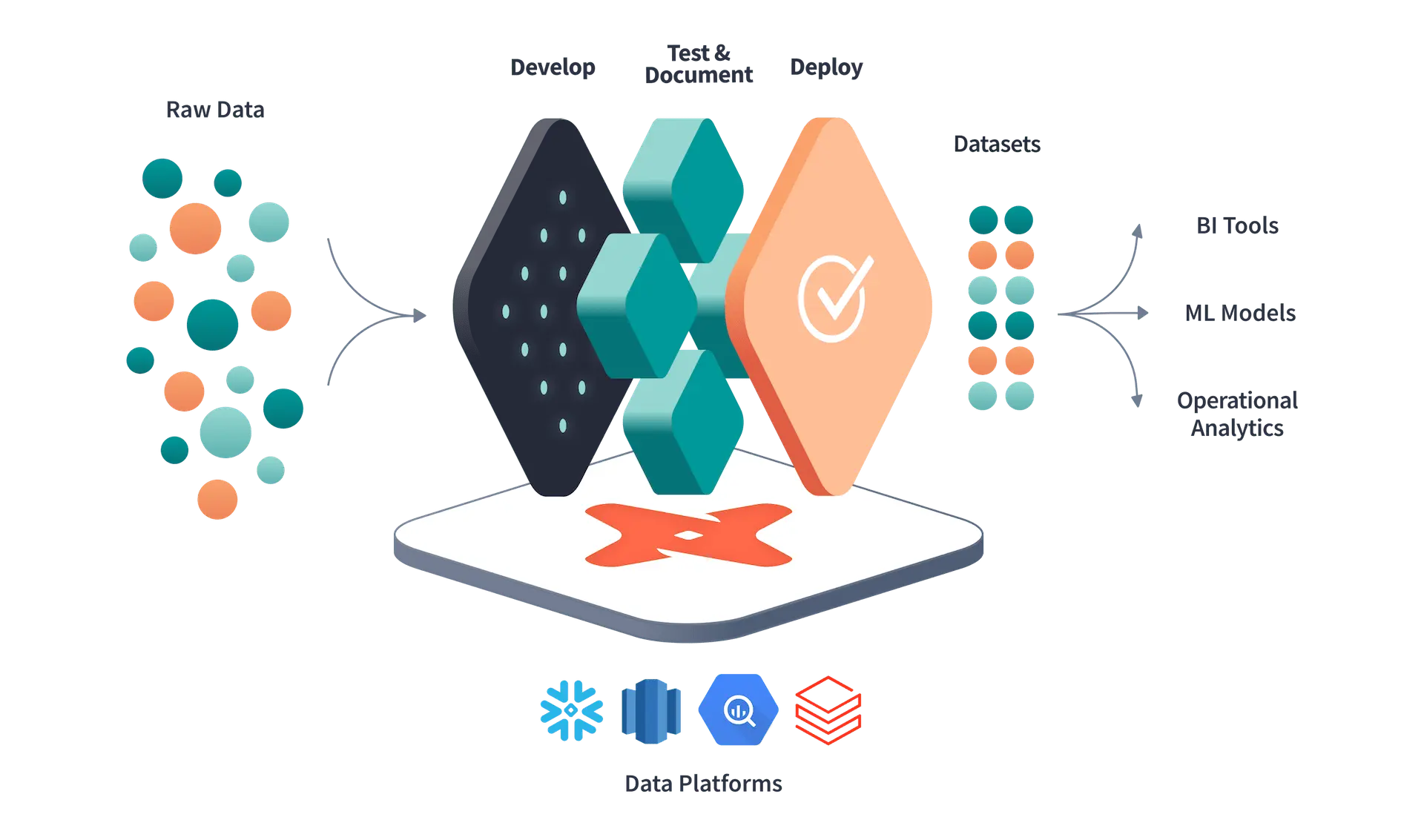
Enhancing dbt Development with Automated PR Validation in Azure Pipelines
In the fast-paced world of data engineering, maintaining high-quality, consistent code is crucial. As teams grow and projects scale, the need for thorough validation of pull requests (PRs) becomes even more important. This ensures minimal errors, enforces best practices, and guarantees seamless deployments.
This blog post explores how to build a robust Continuous Integration (CI) pipeline specifically tailored for dbt projects. By automating PR validation with Azure Pipelines, dbt tests, and SQLFluff, teams can significantly improve efficiency, solidify code consistency, and reduce the risk of errors slipping into production.
Understanding Azure Pipelines
Azure Pipelines, similar to GitHub Actions, GitLab CI, and Jenkins, is Microsoft's cloud-based CI/CD service that automates building, testing, and deploying code. It works by defining workflows in YAML files, which specify the steps needed to validate and deploy code changes. These pipelines can be triggered automatically when code is pushed or pull requests are created, making them ideal for automated validation workflows.
What is dbt?

At its core, dbt (data build tool) is the data engineer’s Swiss Army knife for transforming raw data into analytics-ready gold. It’s an open-source tool designed to help teams write modular, version-controlled SQL code that’s easy to understand, test, and share.
Think of dbt as the bridge between your data warehouse and meaningful insights. By leveraging the power of SQL and a little bit of software engineering magic, dbt allows you to:
- Transform Data: Turn messy, raw data into clean, modeled tables ready for analysis.
- Version-Control Code: Keep your transformation logic organized and trackable with Git integration.
- Test Your Work: Implement rigorous testing to ensure your models deliver consistent and accurate results.
- Document Effortlessly: Automatically generate comprehensive documentation for your data models.
dbt shines in environments where data pipelines can grow messy or unwieldy. It encourages software engineering best practices, like modularity and testing, while remaining approachable for SQL-savvy analysts.
In short, dbt isn’t just a tool; it’s a movement empowering teams to own their transformation layer with confidence and agility. Now, let’s dive into how you can supercharge your dbt workflows with automated PR validation.
Automated PR Validation Pipeline: Addressing Key Challenges
Implementing an automated PR validation pipeline tackles several challenges head-on. By leveraging Azure Pipelines, teams can:
- Validate dbt models to ensure data integrity.
- Enforce SQL standards for consistent code quality across the project.
- Focus code reviews on business logic rather than syntax.
- Prevent resource conflicts through sequential execution.
- Target validation of only modified files for enhanced efficiency.
This fosters a more streamlined and error-free development process.
Overview of the Build Validation Pipeline
The build validation pipeline automates the verification of dbt models and SQL code to maintain quality and consistency before changes are merged.

Key Steps:
- Identify Changes: Uses Git to identify modified SQL and YAML files, optimizing validation.
- Validate Models: Executes
dbt parseanddbt run --emptyto verify schema definitions and documentation. - Enforce Code Quality: Uses SQLFluff to ensure SQL formatting standards.
- Sequential Execution: Ensures orderly processing to prevent conflicts.
Pipeline Breakdown
1. Triggering and Setup
The pipeline is triggered by PR creation. Initial steps include:
- Secure Configuration: Downloads the
dbt_profiles.ymlfile for secure credentials. - Repository Checkout: Performs a deep clone of the repository.
2. Identifying Changes
The pipeline efficiently identifies modified SQL and YAML files using Git:
- script: |
cd $(project_root)
changed_sql_files=$(git diff --name-only --diff-filter=AM origin/$(System.PullRequest.targetBranchName) |
grep '^$(project_root)/models/.*\.sql$' |
tr '\n' ' ')
echo "##vso[task.setvariable variable=changed_sql_files]$changed_sql_files"
displayName: 'Detect Changed SQL Files'
This targeted approach optimizes validation by focusing on specific changes.
3. Dependency Installation
To validate dbt models, the pipeline installs necessary dependencies:
- script: |
pip install dbt-core==$(dbt_core_version) dbt-snowflake==$(dbt_snowflake_version) sqlfluff-templater-dbt==$(sqlfluff_version)
displayName: 'Install Dependencies'
This process ensures:
- Version consistency across tools.
- Proper error handling for smooth execution.
- Efficient setup tailored to the project’s requirements.
Validating dbt Models and Code Quality
4. Model Validation
To ensure the integrity and accuracy of dbt models, the pipeline employs two key validation steps:
Syntax Validation:
Verifies the correctness of syntax and references within dbt models.
Employs dbt parse to analyze the model structure.
Identifies potential errors early in the development process.
Implementation:
- script: |
cd $(project_root)
dbt parse
displayName: 'Validate Syntax with dbt Parse'
dbt Model Validation:
Syntax Validation: Uses dbt parse to check for errors in dbt model syntax.
Dry-Run Testing: Executes dbt run --empty to simulate model execution without reading production data.
Utilizes dbt run with the --empty flag to simulate execution without real data.
Validates model logic and identifies potential issues.
Implementation:
- script: |
dbt run --select $(changed_sql_files_base) --target CI --full-refresh --empty
displayName: 'Dry-Run Validation'
5. Code Quality with SQLFluff

SQLFluff is a powerful linter that enforces consistent SQL formatting and best practices:
- script: |
cd $(project_root)
sqlfluff lint $(changed_sql_files)
displayName: 'Lint SQL Files with SQLFluff'
By enforcing consistent formatting and identifying potential issues early, SQLFluff significantly improves:
- Code Readability: Consistent formatting enhances code understanding.
- Maintainability: Standardized code is easier to maintain and modify.
- Overall Quality: Early identification of issues reduces the risk of errors.
6. Setting Source Database
To ensure the accuracy of schema definitions and documentation, the pipeline manually sets Source Database:
- script: |
cd $(project_root)
find . -name "*.yml" -type f | while read -r file; do
sed -i 's/{{target\.database}}/$(prod_database)/g' "$file"
done
displayName: 'Validate YAML Files'
This step ensures:
- Data Accuracy: Ensures the pipeline uses the correct and up-to-date source database.
- Consistency: Keeps schema and data definitions consistent across environments.
- Schema Integrity: Guarantees accurate schema and documentation for downstream processes.
7. Sequential Execution

To maintain order and prevent resource conflicts, the pipeline enforces sequential processing:
trigger: none
lockBehavior: sequential
variables:
- group: dbt_build_validation
This configuration guarantees:
- Resource Efficiency: Prevents multiple pipeline instances from running concurrently.
- Reliable Validation: Ensures that validation processes are completed in a predictable order.
- Consistent Results: Maintains the integrity of validation results.
By combining these validation steps and enforcing sequential execution, the pipeline ensures the quality, consistency, and reliability of dbt models and SQL code. This approach is especially critical because dbt Core does not support concurrent runs out of the box, meaning multiple runs at the same time can lead to conflicts or unexpected behavior. Sequential execution avoids these pitfalls, ensuring a smooth and predictable validation process.
Full Pipeline Configuration
trigger: none
# Input variables:
lockBehavior: sequential # Ensure that only one instance of the pipeline runs at a time
variables:
- group: dbt_build_validation
pool:
vmImage: ubuntu-latest
steps:
# Download secure dbt profiles.yml only if there are changed files
- task: DownloadSecureFile@1
name: dbt_profile
displayName: 'Download dbt profiles.yml'
inputs:
secureFile: 'CI_profiles.yml'
# Checkout the repository first to get the necessary files for comparison
- checkout: self
fetchDepth: 0
persistCredentials: true
# Determine changed and added files from the current branch
- script: |
cd $(project_root)
# Get full paths and store as space-separated list for changed SQL files
changed_sql_files=$(git diff --name-only --diff-filter=AM origin/$(System.PullRequest.targetBranchName) |
grep '^$(project_root)/models/.*\.sql$' |
sed 's|raisa_dbt|.|g' |
tr '\n' ' ')
# Get base names without .sql extension and wrap with +fileName+
changed_sql_files_base=$(git diff --name-only --diff-filter=AM origin/$(System.PullRequest.targetBranchName) |
grep '^$(project_root)/models/.*\.sql$' |
xargs -I {} basename {} .sql |
sed 's/.*/"@"&" "/' |
tr '\n' ' ' |
sed 's/"//g')
echo "##vso[task.setvariable variable=changed_sql_files]$changed_sql_files"
echo "##vso[task.setvariable variable=changed_sql_files_base]$changed_sql_files_base"
# Output for debugging
echo "Changed and added files (full paths): $changed_sql_files"
echo "Changed and added files (base names): $changed_sql_files_base"
displayName: 'Get changed SQL files'
# Determine changed and added YAML files from the current branch
- script: |
cd $(project_root)
# Get full paths and store as space-separated list for changed YAML files
changed_yaml_files=$(git diff --name-only --diff-filter=AM origin/$(System.PullRequest.targetBranchName) | grep '^$(project_root)/models/.*\.yml$' | tr '\n' ' ')
echo "##vso[task.setvariable variable=changed_yaml_files]$changed_yaml_files"
# Output for debugging
echo "Changed and added YAML files (full paths): $changed_yaml_files"
displayName: 'Get changed YAML Files'
# Install required dependencies for dbt and sqlfluff only if there are changed files
- script: |
set -ex
pip install dbt-core==$(dbt_core_version) dbt-snowflake==$(dbt_snowflake_version) sqlfluff-templater-dbt==$(sqlfluff_version)
displayName: 'Install dbt and sqlfluff dependencies'
condition: and(succeeded(), or(ne(variables['changed_sql_files'], ''), ne(variables['changed_yaml_files'], '')))
# Prepare dbt profiles.yml only if there are changed files
- script: |
cd $(project_root)
mkdir -p ~/.dbt
cp $(dbt_profile.secureFilePath) ~/.dbt/profiles.yml
dbt deps
displayName: 'Copy dbt profiles.yml'
condition: and(succeeded(), or(ne(variables['changed_sql_files'], ''), ne(variables['changed_yaml_files'], '')))
# Only parse dbt models if there are changed files
- script: |
cd $(project_root)
dbt parse
displayName: 'Parse dbt models for changed and added files'
condition: and(succeeded(), or(ne(variables['changed_sql_files'], ''), ne(variables['changed_yaml_files'], '')))
# Lint changed and added files with sqlfluff only if there are changed files
- script: |
cd $(project_root)
echo $(changed_sql_files)
sqlfluff lint $(changed_sql_files)
displayName: 'Lint issues in changed files with sqlfluff'
condition: and(succeeded(), ne(variables['changed_sql_files'], ''))
# Run dbt for changed and added files with full-refresh only if there are changed files
- script: |
cd $(project_root)
echo $(changed_sql_files_base)
find . -name "*.yml" -type f | while read -r file; do
sed -i 's/{{target\.database}}/$(prod_database)/g' "$file"
done
echo "Replacement complete for all .yml files."
dbt run --select $(changed_sql_files_base) --target CI --full-refresh --empty
displayName: 'Empty run dbt for changed and added files'
condition: and(succeeded(), ne(variables['changed_sql_files'], ''))
Key Advantages
- Faster Feedback Loops: Rapid identification and resolution of issues.
- Improved Code Quality: Consistent formatting, enhanced readability, and adherence to best practices.
- Efficient Collaboration: Streamlined PR reviews and reduced manual effort.
- Reduced Risk of Errors: Early detection and prevention of potential problems.
Best Practices for Pipeline Optimization
- Regular Maintenance: Keep the pipeline up to date with the latest dbt and SQLFluff versions.
- Team Collaboration: Establish clear guidelines for PR submissions and code reviews.
- Performance Optimization: Fine-tune the pipeline to minimize execution time and resource consumption.
Conclusion
By automating PR validation, organizations can significantly improve their data engineering workflows. This streamlined approach leads to higher code quality, faster development cycles, and reduced risk of errors.
Next Steps
To further enhance your dbt development practices, consider these additional strategies:
- Expand Test Coverage: Implement comprehensive testing scenarios to identify potential issues early.
- Customize SQLFluff Rules: Tailor linting rules to match specific organizational standards.
- Integrate with End-to-End Pipelines: Seamlessly integrate the validation pipeline with deployment and monitoring processes.
- Automate Documentation Validation: Ensure documentation stays up-to-date and accurate.
- Lint and Validate Python Models: Ensure Python models are properly linted and validated as part of the pipeline.
- Parse if MD Files Changed: Detect and handle changes in markdown files to trigger appropriate actions.
- Seed --full-refresh if Seed Files Change: Implement a full-refresh for seed files when changes are detected.
By embracing automated PR validation, you can elevate your data engineering team's efficiency and deliver high-quality data products.