Recording Data History Between The Application Level and SQL Server Temporal Tables (part 1)


Imagine logging into your application's database and finding a change in a data record that just doesn’t make any sense. You trace the application code, check for any bugs, sit with the users, try reproducing the change and all of this doesn't get you anywhere!
Wouldn't it give you a head start in your debugging process if there was a way to find out when the record changed and how it looked like before that change?
There are many ways to store your application’s historical data in SQL Server. Some people prefer doing this directly from the application level, others prefer using some of SQL Server's features such as Temporal Tables, Change Data Capture, Triggers and Change Tracking. In this article we will be talking about two approaches: saving historical records directly through your application code versus doing so using SQL Server Temporal Tables.
Example:
The example we will discuss in this article is the database for school students’ grades. We will be focusing on the table that keeps the final grades and how the history of the grades per student can be recorded. The grades are entered by teachers along the semester, and they are reflected on the FinalGrade table for each student to see where they stand. For simplicity I will not use any foreign keys. The FinalGrade table will look something like this:

This table contains each student’s final grades for the semester. Each time a teacher enters a new grade, say a quiz worth 10 points, the final grade is updated to reflect this addition. All these records were created on the first day of the semester, January 10th in our case. All the grades are originally set to 0 for all students. At the end of the semester these records will look something like this:

Goal: Catch the history that led the records to be the way they are. For example, Layla has a total of 533 points. If we want to know the history of how this record reached the current state, how would we save these steps?
Application Side History Recording:
In this approach, the design simply revolves around the idea that the logic of saving the historical record is done from the application side. There are two ways of keeping the historical data in the database:
- We can either keep them in a separate table, for instance “FinalGradeHistory”, and choose the table’s schema as we want. We can also have a foreign key in the history table to the record in the main table for which this history record was inserted. This separate table can be in the same database or in a different one for better performance.
- We can keep them in the same table and use “Effective Dating”. That is, each record will have an Effective Start Date and an Effective End Date. The most recent record in this case will have the Effective End Date = null. In some cases, if the dates are not needed, we can just have a boolean value for each record “IsEffective” to identify whether it is effective or not.
Applying the "Separate Table" way:
The goal is to save the history data to the FinalGradeHistory table.
1. Create the database table in which the history will be kept. As mentioned before, we can use whichever schema we want. I chose not to add the CreatedBy and CreatedAt columns because the data would be redundant. The CreatedBy and CreatedAt in our case are going to be the same for the lifetime of each record.
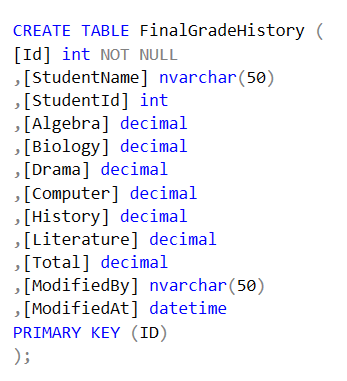
2. Now to the application level, each time there is an update or delete statement applied to the FinalGrade table, there must be an insert statement to the FinalGradeHistory table to capture the old values. The insertion to the history table will simply be a copy of the already existing record before the update. The update function would look something like this:

3. After some updates to the FinalGrade table, querying the FinalGradeHistory table by running
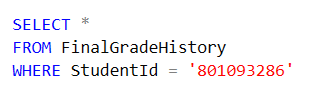
should give us something like this:

Pros:
- Flexibility and control over what to save and what to discard. For example, if we choose to keep the data in a separate table, we can choose the schema we want as some data from the main table might be irrelevant and redundant if kept in the history table.
- Ability to record who did the modification. To do that, you could simply get the user id from the database context in your application level and save it in the historical record before inserting it to the database. We will see that this is not as simple in the Temporal Tables approach.
Cons:
- As they say, with great power comes great responsibility. While this approach gives the developer control over what to save, they need to be sure that each time the application level writes into the main table, it saves the history as well. The logic needs to be applied with every update and delete.
- In case of running scripts directly on the database, changes are not going to be reflected automatically on the history table. It will be the responsibility of the developer to cover recording the history in this case as well. This is a problem we will not face with Temporal Tables.
- If “Effective Dating” is used, the main table can get too big, which might eventually affect performance.
- It does not tell you directly what changed. If you need to know which field(s) specifically changed, you will need to compare the latest record with the latest history record.
Final thoughts:
Although using the application-level approach might work as a charm for some systems, it might be a headache for others. The goal is to choose the better fit for your system; what works best for your data, what exactly do you want to capture, how much effort are you willing to put to maintain these tables and so on.
Now that we are aware of this approach's strengths and weaknesses, what advantages do Temporal Tables have to offer? Which disadvantages raise a flag and could be a reason to why you would want to use this way over the other? Let's talk more about Temporal Tables in Part 2!