Text Similarity Analysis at Scale



Think of your data as a giant puzzle, where the pieces often wear clever disguises. As a data engineer, you're often left trying to put the pieces back together, but there's a catch - you have thousands of pieces to sift through.
Here's where text similarity can be a handy tool. It can be your magnifying glass, helping you spot the hidden connections more efficiently and making your insights sharper.
In this article, we will explore different approaches to find the extent to which certain words/sentences can be similar. We will delve into the world of text similarity analysis, leveraging the power of Snowflake, a versatile data warehouse. We chose Snowflake for this task because of its exceptional scalability, both vertically and horizontally, making it the ideal tool to tackle text similarity on a massive scale.
Topics
- Understanding Text Similarity
- Text Similarity Metrics
- Use Cases
- Benchmarking for Differnt Warehouse Sizes
- Conclusion
Understanding Text Similarity
Similarity is the process of determining the extent to which two items are similar. For example, consider two cars: you have many ways to compare them, such as color, shape, brand and various other features.

When it comes to Text Similarity specifically, you are exploring similarity on two different dimensions - semantically and lexically.
- Semantic similarity focusses on the meaning behind the words.
- Lexical similarity focusses on the words by themselves, considering factors like letter and word frequency, as well as the presence of any missing letters (e.g. William -> Williams).
For example: The mouse ate the cheese.
- The cat ate the mouse. (Similar in wording but different in meaning)
- The rat consumed the cheese. (Different in wording but Similar in meaning).
In this article, We will focus on the Lexical similarity between two sentences/words.
Text Similarity Metrics
There are multiple metrics to find if two strings are similar. We will use sql on Snowflake Data Cloud to discuss the most commonly used metrics, leveraging their text similarity built-in functions' capabilities.

1. Jaccard Index
Jaccard Index (also known as Jaccard Similarity coefficient) is used to compare between two distinct sets of words. It provides a metric ranging from 0% to 100%. The higher the metric the closer the two strings are to each other.
It's calculated by dividing the intersection of the two sets against their union.
$$ J(A,B) = { |A\cap B| \over |A\cup B| } $$
Example:
A: "Raisa Energy is a leading oil & gas investment and management company"
B: "Raisa Energy company is focused on oil & gas investment"
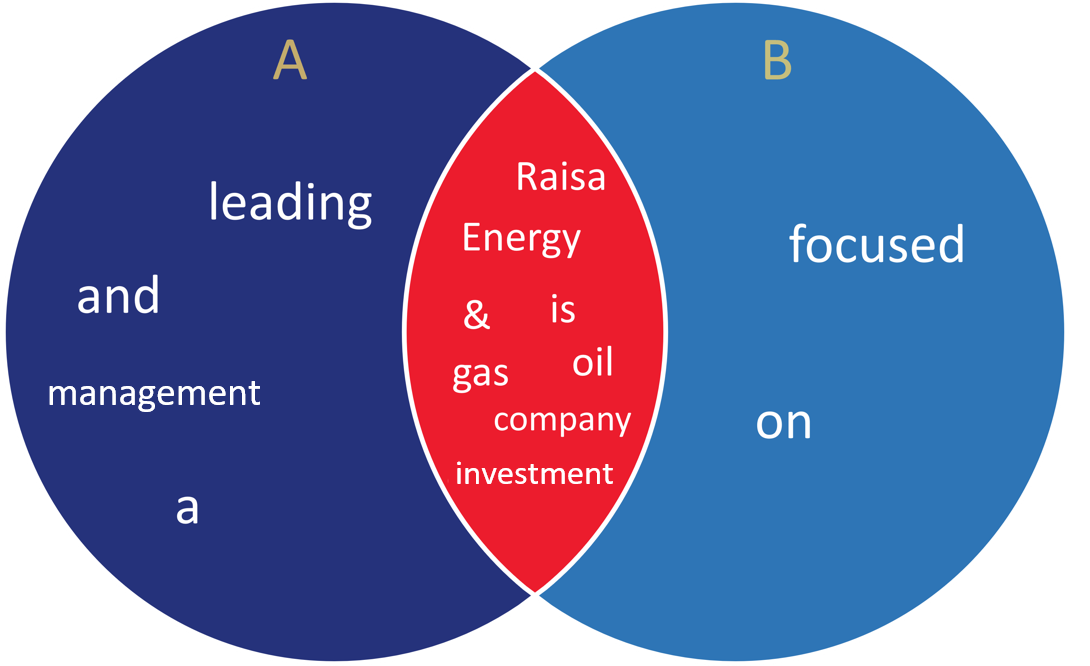
$$ J(A,B) = {|{A\cap B}| \over |{A}{\cup} {B}| } = {{8} \over {4}+{8}+{2}} = 57\% $$
Snowflake Example:
CREATE TEMP TABLE JACCARD_INDEX_EXAMPLES (TEXT_A VARCHAR, TEXT_B VARCHAR);
INSERT INTO JACCARD_INDEX_EXAMPLES (TEXT_A,TEXT_B)
VALUES
('I love dogs and cats','I love cats'),
('Coding is great','I Hate Coding'),
(
'Raisa Energy is a leading oil & gas investment and management company',
'Raisa Energy company is focused on oil & gas investment'
),
('Well Name 10 15 20H','Name Well 10 15 J 20HX'),
('Did you sleep well ?', 'Are you well ?')
;
SELECT
TEXT_A,
TEXT_B,
-- split by the spaces and take only the distinct words
ARRAY_DISTINCT(SPLIT(LOWER(TEXT_A),' ')) TEXT_A_TOKENS,
ARRAY_DISTINCT(SPLIT(LOWER(TEXT_B),' ')) TEXT_B_TOKENS,
-- the intersection between the two texts
ARRAY_INTERSECTION(TEXT_A_TOKENS,TEXT_B_TOKENS) TEXT_INTERSECTED_TOKENS,
-- the union by concatenating the two texts tokens and get the distinct tokens
ARRAY_DISTINCT(ARRAY_CAT(TEXT_A_TOKENS,TEXT_B_TOKENS)) TEXT_UNION_TOKENS,
ARRAY_SIZE(TEXT_INTERSECTED_TOKENS) / ARRAY_SIZE(TEXT_UNION_TOKENS) * 100 JACCARD_INDEX
FROM JACCARD_INDEX_EXAMPLES;
SPLIT:Splits a given string with a specified separator and returns the result as an array of strings.
LOWER: Returns the input string with all characters converted to lowercase.
ARRAY_DISTINCT: Excludes any duplicate elements that are present in the input array.
ARRAY_INTERSECTION: Returns an array that contains the matching elements in the two input arrays.
ARRAY_CAT: Returns a concatenation of two arrays.

Note:
keep in mind that the Jaccard similarity is a basic measure of similarity that simply considers the presence or absence of words in the texts. The frequency or order of the words are not taken into consideration. You might want to look at more complex similarity measurements depending on your particular use case.
2. Levenshtein Distance
Levenshtein Distance (aka Edit Distance) is used to compare between two texts. It gives a score from 0 to infinity (∞). The lower the score the more similar the two texts are to each other.
It counts the minimum number of single character changes (insertions, deletions or substitutions) to convert the source text to the target text.
Example:
- raesa → raisa (substitution of 'e' for 'i')
- raisas → raisa (deletion of 's' at the end)
- aisa → raisa (insertion of 'r' at the beginning)
All of those examples have a distance of 1.

Snowflake Example:
CREATE TEMP TABLE LEVENSHTEIN_DISTANCE_EXAMPLES (TEXT_A VARCHAR, TEXT_B VARCHAR);
INSERT INTO LEVENSHTEIN_DISTANCE_EXAMPLES (TEXT_A,TEXT_B)
VALUES
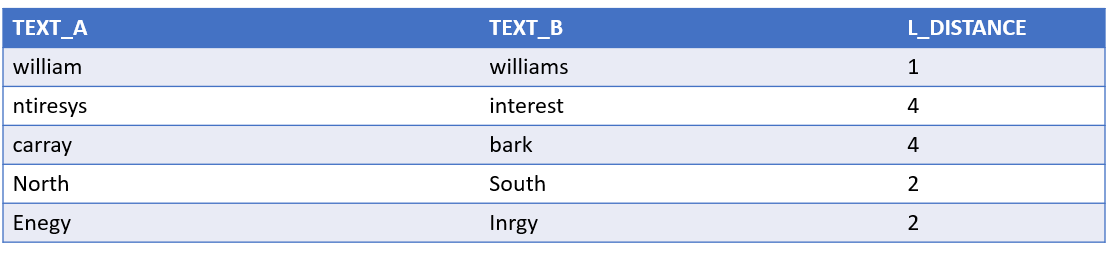
('william','williams'),
('ntiresys','interest'),
('carray','bark'),
('North','South'),
('Energy', 'Inrgy')
;
SELECT
TEXT_A,
TEXT_B,
-- Get the L. distance between the two texts by snowflake built-in function
EDITDISTANCE(TEXT_A,TEXT_B) L_DISTANCE
FROM LEVENSHTEIN_DISTANCE_EXAMPLES;
EDITDISTANCE: Computes the Levenshtein distance between two input strings. It is the number of single-character insertions, deletions, or substitutions needed to convert one string to another.
Note:
Unlike some other metrics (e.g. Damerau-Levenshtein distance), character transpositions are not considered.
3. Jaro-Winkler
Jaro-Winkler Similarity is used to compare between two texts, providing a score from 0% to 100%. The higher the score the more similar the two texts are to each other.
It's similar to Levenshtein Distance, but takes into consideration the number of transpositions between characters.
Note:
There is a metric called 'Jaro' which 'Jaro-Winkler' is based upon.
The difference is that 'Jaro-Winkler' takes into account the common substring prefix between the two texts.
$$
Jaro~Similarity =
sim_j = \begin{cases}
0 & \text{if } m = 0 \\
{1 \over 3}({m \over |s_1|}+{m \over |s_2|}+{m-t \over m}) & \text{otherwise}
\end{cases}
$$
$$
JaroWinkler =
sim_w = sim_j + l * p * (1-sim_j)
$$
- Si: Length of word.
- m: Number of matching characters.
- t: Number of transpositions.
- l: length of common prefix at the start of the string up to max of 4.
- p: Constant Scaling Factor should not exceed .25(if l is max at 4), Standard Value = 0.1.
Example:
Src Word: 'risaa', Target Word: 'raisa'

$$
sim_j ={1 \over 3}({5 \over 5}+{5 \over 5}+{5-2 \over 5})= 86.67\%
$$
$$
sim_w = .8667 + 1 * 0.1 * (1-.8667)= 88\%
$$
Snowflake Example:
CREATE TEMP TABLE JARO_W_EXAMPLES (TEXT_A VARCHAR, TEXT_B VARCHAR);
INSERT INTO JARO_W_EXAMPLES (TEXT_A,TEXT_B)
VALUES
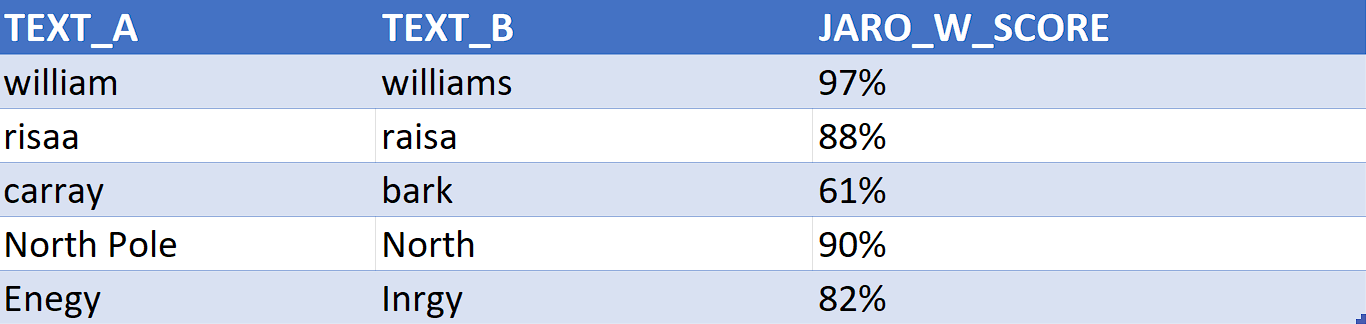
('william','williams'),
('risaa','raisa'),
('carray','bark'),
('North Pole','North'),
('Energy', 'Inrgy')
;
SELECT
TEXT_A,
TEXT_B,
-- Get the jaro-winkler score between the two texts by snowflake built-in function
JAROWINKLER_SIMILARITY (TEXT_A,TEXT_B) JARO_W_SCORE
FROM JARO_W_EXAMPLES;
JAROWINKLER_SIMILARITY: Computes the Jaro-Winkler similarity between two input strings. The function returns an integer between 0 and 100, where 0 indicates no similarity and 100 indicates an exact match.
Note:
- The similarity computation is case-insensitive.
- For short strings, Runtime Complexity is O(|S1|*|S2|).
- For long strings, Runtime Complexity is O(MAX(|S1|,|S2|)).
Use Cases
- Jaccard Index - Tailored for Relevance 📜:
- Search Engines: It excels in search engines by measuring the relevance of documents to user queries, helping deliver precise search results based on common terms.
- Recommendation Systems: Jaccard Index shines in e-commerce, suggesting products based on user interests and attributes, enhancing personalized recommendations.
- Levenshtein Distance – Typo Terminator 🤖:
- Typo Correction: Levenshtein Distance is the go-to tool for spell-checkers and auto-correct systems, quietly fixing typing errors in various applications.
- Auto-Complete: It speeds up text input by predicting the next word you're likely to type, making your typing experience smoother.
- Bioinformatics: In genetics, it's an indispensable detective, uncovering tiny mutations in DNA or protein sequences.
- Jaro-Winkler - The Data Matchmaker 🕵️:
- Record Linkage: Jaro-Winkler's strength lies in data integration and record linkage tasks, where it excels at identifying matching records across different datasets, even when there are minor differences or typos.
- Name Matching: It's a powerful tool for finding similar names in databases, ensuring accurate identification, and reducing duplicates.
- Geographic Data Matching: In geographic information systems (GIS), Jaro-Winkler ensures precise matching of place names, even when there are slight variations, enhancing data accuracy.
Benchmarking Jaro-Winkler Similarity Scores for Different Warehouse Sizes
We've explored different similarity techniques, navigating the accuracy trade-offs that each one introduces based on varying use-cases. Now, let’s dive into a real-world scenario. Imagine you have a sample dataset with n rows, and the desire to find the similarity of each of these rows against a fixed reference dataset with m rows. The plan? A classic cross join of n and m, calculating a score for each pair, and cherry-picking the highest one. But, of course, this comes with a potential price tag.
If we opt for Jaro-Winkler as the chosen similarity technique for our use-case, what's the price tag for using different sample datasets against a substantial 2.5M rows reference dataset? And how does this cost fluctuate with the size of our warehouse? Let's dig into the numbers and draw some insights.
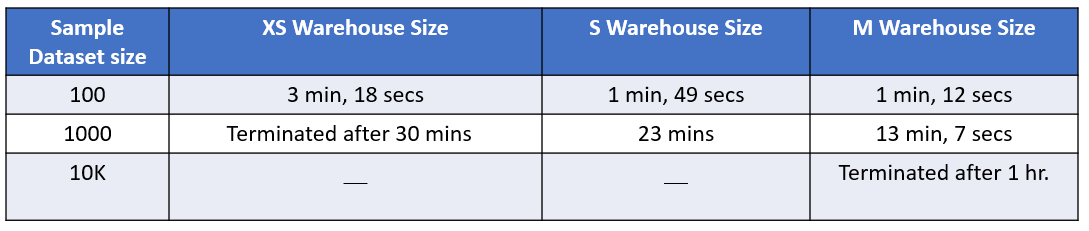
This experiment shows a positive correlation between scaling up the warehouse size and performance improvement, thanks to augmented computing resources. A larger warehouse size means more processing power, memory, and storage capacity. When dealing with extensive cross joins and similarity score calculations, having more resources allows the database to handle the computational load more efficiently. However, it's crucial to note that this enhancement comes at a monetary cost.
In weighing the pros and cons, if budget constraints or time considerations are factors, and expanding computational resources might not align with your goals, this approach may warrant reconsideration - especially if your sample data scales considerably. As with any technological choice, the decision ultimately depends on the specific needs, priorities, and constraints of your project. Evaluating the trade-offs and considering alternative approaches will guide you to the most suitable solution for your text similarity requirements.
Conclusion
In conclusion, exploring text similarity in Snowflake can unlock a range of possibilities. By utilizing powerful algorithms and leveraging Snowflake's user-friendly environment, you can easily implement text similarity analysis without the need for extensive programming. Snowflake's streamlined approach empowers users to uncover insights, make data-driven decisions, and extract valuable information from textual data efficiently. Snowflake provides a simplified yet robust solution for text similarity tasks, enabling users to harness the power of text analysis with ease.
Our goal was to introduce you to the practical examples of text similarity in Snowflake. These algorithms are powerful and usually involve complex programming in any language, even with the available libraries, but Snowflake makes their implementation incredibly straightforward.
Want to Know More?
Check out these links: