Cost-Efficient Text-to-SQL Chatbot Using ChatGPT LLMs




Overview
Have you ever wondered how to make data more accessible to other employees in your organization without them having to deal with the headache of SQL queries? We would like to share with you our attempt at solving this problem by making a cost-efficient Text-to-SQL chatbot at Raisa.
In this article we begin by introducing the Text-to-SQL task, current best approaches to the problem, and how our implementation balances accuracy with cost-effectiveness. Without further ado, let's get into business!
Introduction

The main goal of Text-to-SQL chatbots is to provide users with a natural language interface to relational databases. This eliminates the burden of learning SQL and makes data more accessible to users.

The general steps of a Text-to-SQL chatbot are to take the user question in English, create the corresponding SQL query that answers the question, and finally execute the query on the database and return the result to the user.
Historically, researchers have tried to tackle the Text-to-SQL task using multiple approaches that can be categorized into rule-based approaches, training/fine-tuning approaches, and in-context learning approaches tied to LLMs.
Rule-based approaches require manually created logic, are difficult to implement, and only achieve good accuracy in specific cases. On the other hand, training/fine-tuning approaches revolve around training language models or fine-tuning pre-trained models on a more specific task. Finally, in-context learning involves the user instructing a language model on how to perform tasks through the prompt itself. This approach has recently flourished with the emergence of LLMs.
Since rule-based approaches depend on manual logic which can be difficult and impractical to apply, we can say that the following table summarizes the most promising approaches along with the different methods of deployment.
Approach | Hosting |
Fine-tuning | On-premise |
Fine-tuning | Not On-premise |
In-context learning | On-premise |
In-context learning | Not On-premise |
Literature Survey

When starting a new project in Data Science/Machine Learning it is very instructive to spend some time researching and exploring related benchmarks in order to get a sense of recent advancements and state-of-the-art approaches. In the Text-to-SQL task an important and popular benchmark is the Spider benchmark. Another benchmark that has recently gained popularity is called BIRD which targets more realistic use cases than the Spider benchmark.
Observing the leaderboards for both Spider [1] and BIRD [2], one can notice that LLMs have recently been dominating the top ranks and achieved state of the art results using in-context learning, without the need for any training whatsoever.
Since LLMs show the most promising results, we decided go with in-context learning using efficient prompting techniques rather than using fine-tuning approaches. However, there is still one more question to answer: should we host our own LLM (like Llama 2) on-premises or use LLMs through APIs (like OpenAI)? One way to answer that question is to do a cost-benefit analysis of going down each path, and we can almost always find that hosting LLMs in-house will give a low return on investment when model usage is low (as was our case) [3].
In both the BIRD and Spider benchmarks the leading approach at the time of our research and implementation was the DIN-SQL [4] approach equipped with GPT-4, which we will discuss in detail below.
DIN-SQL Approach
The main idea of the DIN-SQL approach is to decompose the Text-to-SQL problem into smaller sub-tasks which can improve LLM performance by allowing it to solve easier sub-tasks rather than solving the original task all at once. The approach also utilizes chain-of-thought prompting which has been shown to drastically improve LLM performance on various tasks [5].
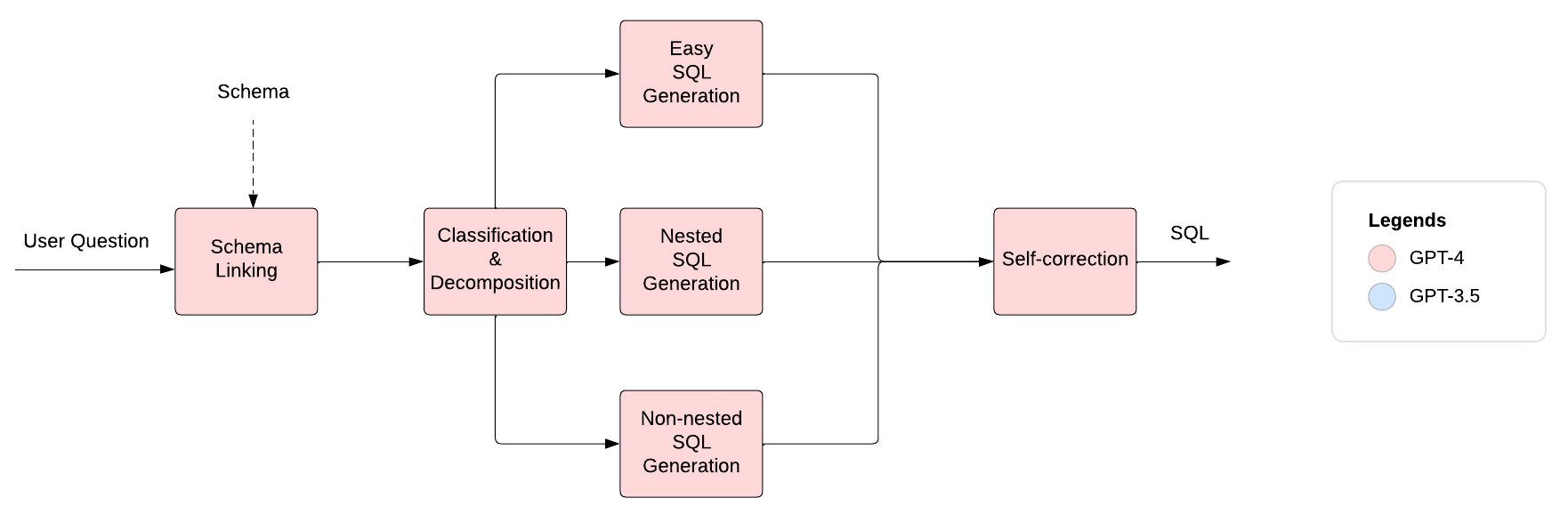
Let's delve more into each step of the DIN-SQL approach:
Schema Linking
The first sub-task is responsible for identifying the columns that will be used from each table as well as condition values for these columns. To do this, the LLM is first given the database schema and the user question, then it is instructed to think step by step and identify the columns and condition values.
To give the LLM a better idea of the required sub-task, 10 examples are given to the model as well. Below, you can find one such example that was given in the prompt.
// Input
Table course, columns = [*,course_id,title]
Table instructor, columns = [*,ID,name,salary]
Table teaches, columns = [*,ID,course_id,semester,year]
Foreign_keys = [course.course_id = teaches.course_id, instructor.ID = teaches.ID]
Q: "Find the id of instructors who taught a class in Fall 2009 but not in Spring 2010."
// Output
A: Let’s think step by step. In the question "Find the id of instructors who taught a class in Fall 2009 but
not in Spring 2010.", we are asked:
"id of instructors who taught " so we need column = [teaches.id]
"taught a class in" so we need column = [teaches.semester,teaches.year]
Based on the columns and tables, we need these Foreign_keys = [].
Based on the tables, columns, and Foreign_keys, The set of possible cell values are =
[Fall,2009,Spring,2010]. So the Schema_links are:
Schema_links: [teaches.id,teaches.semester,teaches.year,Fall,2009,Spring,2010]Classification & Decomposition
In this step, the model tries to predict the complexity of the required SQL which can vary drastically depending on the user question. For example, some SQL queries are very simple while others are more complex and require joining tables and nested queries. Determining the complexity of the required SQL query can be crucial for generating the correct solution.
To do the classification, the LLM is given the columns and the condition values from the Schema Linking step along with the user question. It is then instructed to think step by step and classify the question based on joining and nesting into one of the following types:
- "Easy" query: a simple query that needs one table and doesn't need any nested queries.
- "Non-Nested" query: a query that needs joining multiple tables but doesn't need any nested queries.
- "Nested" query: a query that needs nested queries (may or may not need joining)
10 examples are given to the model here as well, two of which are shown below.
// Input
Q: "Find the buildings which have rooms with capacity more than 50."
schema_links: [classroom.building,classroom.capacity,50]
// Output
A: Let’s think step by step. The SQL query for the question "Find the buildings which have rooms with
capacity more than 50." needs these tables = [classroom], so we don’t need JOIN.
Plus, it doesn’t require nested queries with (INTERSECT, UNION, EXCEPT, IN, NOT IN), and we need
the answer to the questions = [""].
So, we don’t need JOIN and don’t need nested queries, then the SQL query can be classified as
"EASY".
Label: "EASY"// Input
Q: "Give the name and building of the departments with greater than average budget."
schema_links: [department.budget,department.dept_name,department.building]
// Output
A: Let’s think step by step. The SQL query for the question "Give the name and building of the
departments with greater than average budget." needs these tables = [department], so we don’t need JOIN.
Plus, it requires nested queries with (INTERSECT, UNION, EXCEPT, IN, NOT IN), and we need the
answer to the questions = ["What is the average budget of the departments"].
So, we don’t need JOIN and need nested queries, then the the SQL query can be classified as "NESTED".
Label: "NESTED"SQL generation
In this step, the LLM is given the user question and the outputs of all the previous steps and is asked to generate the SQL query. In order to increase the accuracy of SQL generation, the LLM is instructed differently depending on the complexity prediction from the previous step.
- "Easy" query: the model is simply instructed to generate the SQL.
- "Non-Nested" query: the model is instructed to first think step by step about the tables that must be joined, then to generate the SQL.
- "Nested" query: the model is first instructed to think step by step about any necessary sub-queries, then to generate the final SQL.
10 examples are given to the model in each type. The example shown below is for the "Nested" query since this involves the most steps.
// Input
Q: "Give the name and building of the departments with greater than average budget."
Schema_links: [department.dept_name,department.building,department.budget]
// Output
A: Let’s think step by step. "Give the name and building of the departments with greater than average
budget." can be solved by knowing the answer to the following sub-question "What is the average budget
of departments?".
The SQL query for the sub-question "What is the average budget of departments?" is SELECT avg(budget)
FROM department
So, the answer to the question "Give the name and building of the departments with greater than average
budget." is =
Intermediate_representation: select department.dept_name , department.building from department where
@.@ > avg ( department.budget )
SQL: SELECT dept_name , building FROM department WHERE budget > (SELECT avg(budget) FROM department)Self-Correction
The purpose of this final step is to check for any bugs in the generated SQL. The LLM is given the full database schema, the user question, the SQL output from the previous step, and a set of hints, then it is instructed to correct the bugs in the SQL (if any).
// Input
#### For the given question, use the provided tables, columns, foreign keys, and primary keys to fix the given SQLite SQL QUERY for any issues. If there are any problems, fix them. If there are no issues, return the SQLite SQL QUERY as is.
#### Use the following instructions for fixing the SQL QUERY:
1) Use the database values that are explicitly mentioned in the question.
2) Pay attention to the columns that are used for the JOIN by using the Foreign_keys.
3) Use DESC and DISTINCT when needed.
4) Pay attention to the columns that are used for the GROUP BY statement.
5) Pay attention to the columns that are used for the SELECT statement.
6) Only change the GROUP BY clause when necessary (Avoid redundant columns in GROUP BY).
7) Use GROUP BY on one column only.
Table department, columns = [*,Department_ID,Name]
Table manager, columns = [*,Manager_ID,Department_ID,Name,Age]
Foreign_keys = [manager.Department_ID = department.Department_ID]
Primary_key = [department.Department_ID, manager.Manager_ID]
#### Question: How many managers of the departments are older than 56 ?
#### SQL Query
SELECT COUNT(*) FROM department WHERE Age > 56
// Output
#### Fixed SQL Query
SELECT COUNT(*) FROM manager WHERE Age > 56Proposed Approach
Although the DIN-SQL paper achieves incredible accuracy, it does so at a high monetary cost. For example, the paper suggests using GPT-4 to get the highest accuracy. However, the price of using the GPT-4 API is more than 20 times the cost of GPT-3.5 [6], which raises an important question: do we really need to use GPT-4 in every step to achieve good accuracy? Furthermore, are all the steps in the DIN-SQL approach really necessary?
To decrease the cost, we propose two modifications:
- Use GPT-3.5 in as many steps as possible while reserving GPT-4 for the most difficult steps.
- Eliminate and simplify steps which use GPT-3.5 (to make it easier for the model).
Let's discuss the changes in more details:
Simplifying the Steps:
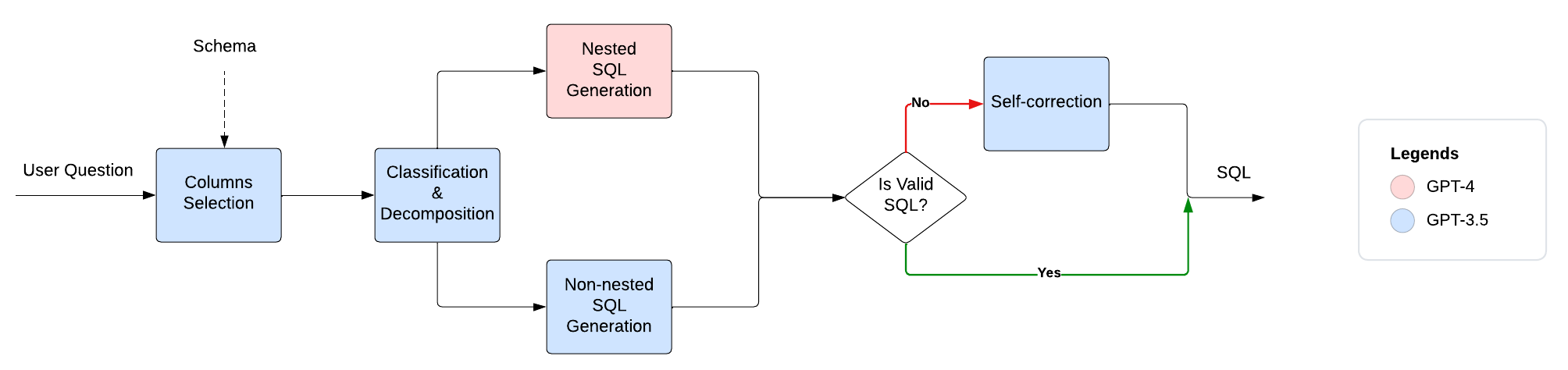
Columns Selection
This step replaces the Schema Linking step in the DIN-SQL approach. The main difference is that the model is only tasked with selecting appropriate columns without having to also identify the condition values for these columns. We also give the model a detailed description for each column which helps a lot with ambiguous column names.
// Input
CREATE TABLE [department] (
[Department_ID] INTEGER NOT NULL, --The ID of the department, a unique id for each department
[Name] varchar(64) NULL, --The name of the department.
CONSTRAINT [PK_department] PRIMARY KEY ([Department_ID])
)
CREATE TABLE [manager] (
[Manager_ID] INTEGER NOT NULL, --The ID of the manager, a unique id for each manager
[Department_ID] INTEGER NOT NULL, --The ID of the department, a unique id for each department
[Name] varchar(64) NULL, --The name of the manager.
[Age] INTEGER NULL, --The age of the manager.
CONSTRAINT [PK_manager] PRIMARY KEY ([Manager_ID])
)
Foreign_keys = [manager.Department_ID = department.Department_ID]
Q: "How many managers of the departments are older than 56 ?"
// Output
A: Let’s think step by step. In the question "How many managers of the departments are older than 56 ?", we
are asked:
"older" so we need column = [manager.Age]
Based on the columns and tables, we need these Foreign_keys = [].
So the needed columns are:
Columns: {"manager": ["Age"]}Classification & Decomposition
For our specific use case, we can further simplify this step since the number of tables used in our POC is no more than three. Any joins between these tables are also all done using the same foreign key.
For these reasons, we can classify query complexity based only on nesting into one of the following types:
- "Non-Nested" query: a query that does not require nested queries.
- "Nested" query: a query that requires nested queries.
This modification simplifies the decomposition step, making it easier to use GPT-3.5, and reduces the number of necessary examples in the prompt, thereby decreasing the cost even more.
// Input
Q: "Find the buildings which have rooms with capacity more than 50."
schema:
CREATE TABLE [classroom] (
[building] varchar(10) NOT NULL, -- The building name, e.g. "Packard"
[capacity] integer NULL, -- The capacity of the building, e.g. "500"
)
// Output
A: Let’s think step by step. The SQL query for the question "Find the buildings which have rooms with
capacity more than 50." doesn’t require nested queries with (INTERSECT, UNION, EXCEPT, IN, NOT IN), and we need
the answer to the questions = [""].
So, we don’t need nested queries, then the SQL query can be classified as
"NON-NESTED".
Label: "NON-NESTED"SQL generation
Similar to the SQL generation step in the original approach, the instructions given to the LLM depend on the predicted SQL complexity.
- "Non-Nested" query: the model is simply instructed to generate the SQL, just like Easy type queries in the DIN paper.
- "Nested" query: the instructions for the Nested queries are kept the same as those in the DIN paper.
// Input
Q: "Find the buildings which have rooms with capacity more than 50."
Schema:
CREATE TABLE [classroom] (
[building] varchar(10) NOT NULL, -- The building name, e.g. "Packard"
[capacity] integer NULL, -- The capacity of the building, e.g. "500"
)
// Output
SQL: SELECT DISTINCT building FROM classroom WHERE capacity > 50Self-correction
This step is similar to the DIN-SQL paper except it's only applied if the generated SQL query gives an error when we try to execute it.
Modifications Summary
The table below summarizes the changes done to the task breakdown of the DIN-SQL paper.
Step | DIN-SQL | Proposed |
Schema Linking | Select columns and condition values | Select columns |
Classification & Decomposition | 3 classes based on joining & nesting | 2 classes based on nesting |
SQL Generation | 3 prompts | 2 prompts |
Self-correction | Applied for each user question | Applied only if the generated SQL gives an error |
Blending between GPT-3.5 & GPT-4:
Since using the GPT-4 API costs 20 times as much as using the GPT-3.5 API, we recommend delegating most of the steps to GPT-3.5 and restricting GPT-4 to only the most difficult steps. We argue that the Nested SQL generation step is the hardest step and therefore only use GPT-4 for generating nested queries.
To gauge our approach's performance, we created a small dataset of around 120 examples, each composed of a user question and a target SQL query. The table below summarizes the results of using three different methods:
- Using GPT-3.5 for all steps
- Using GPT-4 for all steps
- Using GPT-4 only for the Nested SQL generation and using GPT-3.5 otherwise
We can see that the last method reduces the cost significantly compared to using GPT-4 in all the steps while maintaining high accuracy.
Approach | Models | Accuracy | AVG cost per query |
Proposed approach | GPT-3.5 | 75% | $0.010 |
Proposed approach | GPT-4 | 80% | $0.213 |
Proposed approach (blend) | GPT-3.5 + GPT-4 | 78% | $0.062 |
References
[1]: Spider: Yale Semantic Parsing and Text-to-SQL Challenge | Tao Yu et al.
[2]: BIRD-bench | Jinyang Li et al.
[3]: Why choose Llama 2 over ChatGPT? | Damien Benveniste
[5]: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | Jason Wei et al.